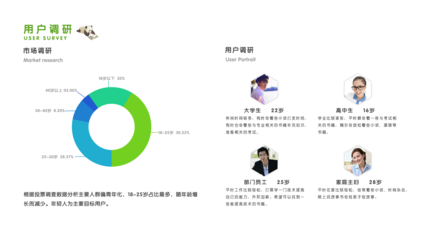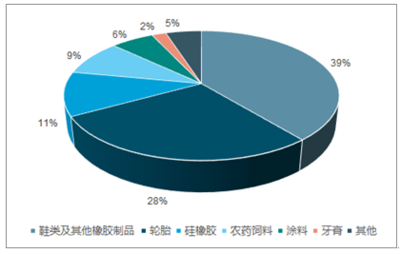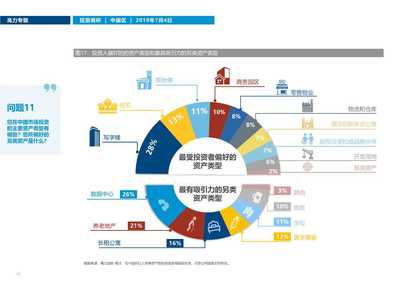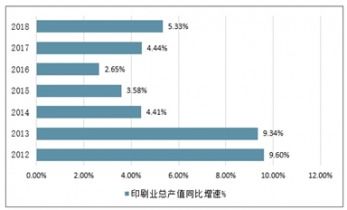
随着移动互联网的深度发展,微信公众号已成为品牌营销、资讯传播和用户互动的重要阵地。海量的公众号文章蕴含着丰富的市场动态、消费者偏好和行业趋势信息。利用Python技术构建微信公众号爬虫,并对抓取的数据进行深度分析,正成为企业进行高效、精准市场调研的一种强大手段。
一、微信公众号爬虫的实现原理与关键技术
微信公众号的官方平台并未提供开放的数据接口供批量获取文章,因此需要通过技术手段进行“非官方”采集。核心实现通常基于以下两种思路:
- 模拟浏览器请求:使用如
Selenium或Playwright等工具,自动化控制浏览器,模拟真实用户登录、搜索、点击、翻页等操作,从而获取动态加载的页面内容。这种方法直观,能应对复杂的JavaScript渲染页面,但速度相对较慢。
- 分析网络请求与接口:通过浏览器的开发者工具(Fitch)分析公众号文章列表及详情的真实数据请求接口(通常是XHR请求)。然后,使用
requests库直接向这些接口发送HTTP请求,并解析返回的JSON数据。这种方法效率极高,是主流方案。关键技术点包括:
- 请求头(Headers)模拟:特别是
User-Agent、Cookie(含登录态)等,以伪装成合法请求。
- 参数构造:公众号的查询接口通常需要
biz(公众号唯一标识)、uin、key等参数,这些需要通过技术手段获取。
- Cookie维护与更新:登录状态的有效期管理是爬虫稳定运行的关键。
一个简化的核心代码框架可能如下:`python
import requests
import json
def fetcharticlelist(biz, uin, key, offset=0):
url = "https://mp.weixin.qq.com/mp/profileext"
params = {
'action': 'getmsg',
'_biz': biz,
'offset': offset,
... # 其他必要参数
}
headers = {
'User-Agent': 'Mozilla/5.0 ...',
'Cookie': '您的Cookie字符串'
}
response = requests.get(url, params=params, headers=headers)
data = response.json()
# 解析data,提取文章列表信息
return parsearticlelist(data)`
二、数据清洗与结构化存储
爬取到的原始数据(HTML或JSON)需要经过清洗和结构化处理,才能用于分析。
- 信息提取:从每篇文章中提取核心字段,如:文章标题、公众号名称、发布日期、阅读数、点赞数(在看数)、留言数、文章正文、文章摘要、原文链接等。可使用
BeautifulSoup或lxml解析HTML,或直接处理JSON。 - 数据清洗:处理缺失值、统一日期格式、去除正文中的HTML标签和无关字符(如广告、二维码提示等)。
- 数据存储:将结构化的数据持久化存储,常用的方式有:
- CSV/Excel文件:适合中小规模数据,便于共享和查看。
- 数据库(如MySQL, PostgreSQL, MongoDB):适合大规模、长期的数据积累与高效查询。
- 数据框(Pandas DataFrame):在内存中直接处理,方便后续分析。
三、基于爬虫数据的市场调研分析维度
获取到清洗后的数据后,可以结合Pandas、NumPy、Matplotlib、Seaborn、Jieba、Scikit-learn等库进行多维度分析,为市场调研提供洞见:
- 竞争格局分析:
- 监测竞争对手:持续抓取竞品公众号的发布动态,分析其发布频率、活跃时段、主要内容类型(产品推广、行业观点、用户故事等)。
- 影响力评估:通过“阅读数/粉丝数”估算打开率,结合“点赞率”、“留言互动率”综合评估竞品内容的影响力和用户粘性。
- 内容策略洞察:
- 爆款内容分析:筛选出高阅读、高互动的文章,利用文本分析(关键词提取、主题模型如LDA)和情感分析,其标题特征、行文结构、情感倾向和核心话题,指导自身内容创作。
- 话题趋势追踪:对不同时间段文章的关键词进行词频统计和趋势绘图,可以发现行业热点话题的兴起与消退周期。
- 用户偏好与市场趋势研究:
- 用户兴趣画像:通过分析头部公众号评论区的高频词汇和情感,间接洞察目标用户群体的关注点、痛点和情绪。
- 新品/活动市场反馈:当竞品发布新品或大型活动时,快速抓取相关文章及评论,分析市场初期反响和口碑。
- 行业声量监测:设定特定关键词(如行业术语、品牌名、产品名),统计其在目标公众号群中出现的频次和趋势,衡量品牌或话题的行业声量。
四、实施中的挑战与伦理考量
- 技术挑战:微信公众号的反爬机制日益严格,包括IP封锁、行为验证、参数加密等,需要设计IP代理池、请求频率控制、验证码识别等策略来应对。
- 法律与伦理风险:
- 遵守
robots.txt:虽然公众号通常未明确设置,但应尊重网站意愿。
- 控制爬取频率:避免对目标服务器造成过大压力。
- 数据使用边界:爬取的数据应仅用于合法的市场分析与研究,不得用于商业侵权、人身攻击或数据贩卖。需特别注意对用户评论等个人信息处理的合规性。
- 知识产权尊重:分析结论可引用,但直接大规模复制传播原创文章内容可能涉及侵权。
结论
利用Python构建微信公众号爬虫并进行数据分析,为市场调研人员提供了一个实时、定量、深度的信息获取与分析工具。它能够将散落于海量公众号中的非结构化信息,转化为关于竞争动态、内容趋势和用户偏好的结构化洞察,极大地提升了市场调研的效率和科学性。在实施过程中,必须平衡技术探索与法律伦理合规,确保数据获取与使用的正当性,方能使其真正成为驱动商业决策的利器。